
序
今天来聊聊jvm中的常量池,相信了解过jvm的朋友,都会知道jvm中存在着常量池这样一块区域,也会知道常量池是用来保存常量的,有了解更加深入的朋友,可能知道常量池在jvm中的位置是在堆上还是在方法区中,再深入可能就不是十分清楚了,所以我想借助这篇文章,和大家一起来理一理常量池。
java中常量池其实是一个比较模糊的概念,因为常量池并不是指代某个特定的用来存储常量的地方,它还是可以细分为 class文件常量池(class constant pool)、全局字符串常量池(string pool或者叫string literal pool)以及运行时常量池(runtime constant pool)。
常量池
class文件常量池
java编译之后的class文件中除了包含了类的版本、字段、方法、接口等描述信息外,还会包含常量池(constant pool),用于存放编译器生成的各种字面量和符号引用,其中字面量就是我们所说的常量,如文本字符串、被申明为final的常量。如下图所示就是class文件中的常量池位置:
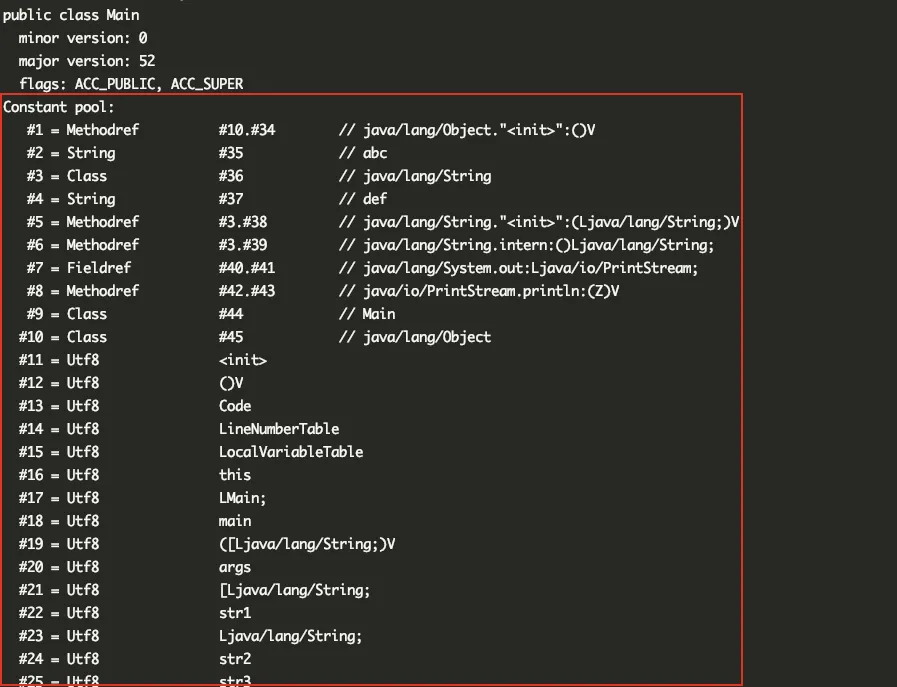
符号引用是一组使用描述符来描述所引用的目标,符号可以是任何形式的字面量,只要使用时能够无歧义地定位到目标即可(它与直接引用区分一下,直接引用一般是指向方法区的本地指针,相对偏移量或是一个能间接定位到目标的句柄)。一般包括下面的三类常量:
- 类和接口的全限定名
- 字段的名称和描述符
- 方法的名称和描述符
常量池的每一项常量都是一个表,一共有14种表示不同表结构的数据,具体可以看一下我之前分享的深入JVM(二)中 常量池 小节。
注:关于符号引用和直接引用的关系不是这里讨论的重点,可以参考知乎上RednaxelaFX的这篇回答
全局字符串常量池
全局字符串常量(又叫字面量,没错就是你理解的字面量)池里的内容是在类加载阶段完成,经过验证,准备阶段之后,在堆中生成字符串对象实例,然后将该字符串对象实例的引用值存储到string pool中,sring pool中存储的是字符串实例的引用值,而不是具体的字面量值,具体的字面量值是在堆中开辟的一块空间存放的。
在HotSpot VM里实现的string pool功能的是一个StringTable,可以类比成一个哈希表,里面存储的是驻留字符串(intern)的引用,也就是说在堆中的某些字符串实例被这个StringTable引用之后,等同于被赋予了"驻留字符串"的身份,这个StringTable在每个虚拟机中只有一份,被所有类共享。
全局字符串常量池一般来说,有如下两种用法:
- 直接使用双引号申明出来的
String对象会存储在常量池中(这里还是啰嗦一句,存储在字符串常量池中的仍然是常量的引用,具体字符串值存储在堆中的)。 - 使用
String提供的intern方法,该方法会从字符串常量池中查询当前字符串是否存在,如果不存在就会将当前字符串放入常量池中。
我们可以简单的使用一个小例子来证明全局字符串常量池的存在:
|
|
如上代码所示,其运行结果如下:
|
|
比较诧异的应该就是第三个结果了,为什么明明自己new了一个值为abc的对象,但是结果却是abd,这就是因为有全局字符串常量池的存在,设想一下,如果没有全局字符串常量池,那么原理应该是下面这样:
在堆中开辟了一块空间用来存储字面量
abc,同时将运行时常量池中的s1变量指向字面量abc的地址,之后执行update()方法的时候,会将堆中的字面量的值由abc变更成abd,但是运行时常量池中的s1所指向的地址没有发生改变,所以第二次输出的结果是abd,此时又重新创建了一个字符串对象s2,同时也会去堆中寻找字面量abc是否存在,由于上一步已经将字面量由abc修改成了abd,所以此时堆中是不存在字面量abc的,因此会重新创建一个新的字面量abc,返回字面量abc地址,再以字面量abc地址为参数,创建了一个新的字符串对象,对象s2则指向新创建的对象地址。所以第三次输出结果依然会是abc,这与真实情况不符。
所以应该是存在着另外一个空间,用来专门存储字符串常量地址,之后运行时常量池中的所有引用都是直接从运行时常量池中获取常量地址,一来这样可以降低运行时常量池和字面量之间的耦合性,二来通过这样的方式可以提高查询效率,将全局字符串常量池数据结构设置成类似hashtable一样的结构之后,每一次只需要在O(1)的时间复杂度内寻找到字面量的地址。
为什么可以这样设计?这是因为在java语言规范中就已经定义,String类型是一个不可以被修改的常量,所以一旦这个字面量被创建,那么这个字面量将永远不会被修改(当然要排除我们上面的那种做法),所以依靠hashtable去查询对应字面量的地址时,对应的key(也就是字面量的值)也是不会发生改变的,在有了这样的限定之后,整个架构的设定得以运行下去。
当然,以上推断目前我只是自己通过查阅相关资料,以及自己手动测试出来的,具体关于全局字符串常量池这个概念,我在《java虚拟机规范》(以下简称规范)中并没有找到十分详细的定义,规范中只是有零星的讲解了相关含义,比如字面量,字符串的驻留等等,关于全局字符串常量池倒是没有详细通过一个片段来说明。所以如果大家有找到比较官方的文档,可以告知我一下~
运行时常量池
运行时常量池(runtime constant pool)是在java文件被编译成class文件之后,将class文件中的class常量池加载到内存中放到运行时常量池中而形成的(该过程发生在加载阶段)。由此可知,运行时常量池是每一个类所独有的,其在将class常量池中的内容加载到内存之后,还会对内存中符号引用进行处理,在经过解析(resolve)阶段之后,运行时常量池中的符号引用会被替换成直接引用,在解析的过程中,会查询全局字符串常量池中的内容,保证运行时常量池所引用的字符串和全局字符串常量池中的引用一致性。
举个例子,看如下代码:
|
|
上面的程序经过编译之后,在该类的class常量池中会存放一些符号引用,然后在类加载之后,将class常量池中存放的符号引用转存到运行时常量池中,然后经过验证,准备阶段之后,在堆中生成驻留字符串实例对象(也就是上面代码中str1所指向的abc实例对象),然后该对象的引用会保存到全局字符串常量池中,最后在解析阶段,要把运行时常量池中的符号引用替换成直接引用,此时就可以直接查询全局字符串常量池中的数据,这样就可以保证运行时常量池中保存的字面量(驻留字符串)地址和全局字符串常量池中的地址一致。
回到上面的例子,现在我们来分析一下,由于字面量abc对应的地址唯一,所以str1和str3地址相同,而实例str2指向的地址是堆内存中的String对象地址,str4中的地址指向的是字面量def的地址,所以很明显str2和str4地址是不同的(这里有一个intern()方法,我们等会详细说明),同理def的字面量地址只有一份,所以str4和str5是相同的。
最后还剩一个问题需要讨论,那就是intern()方法的作用,有心的朋友可能会记得我在上面有说到一个名词–驻留,也提到了全局字符串常量池的两种用法,这里其实就是第二种字符串常量池的使用,intern()方法定义:如果一个字符串类型对象调用该方法,那么该方法会去全局字符串常量池中查询该字符串对象对应的字面量是否存在,如果不存在,那么就在堆中开辟一块空间来存储该字面量,同时将该字面量在堆内存中的地址保存到全局字符串常量池中,最后再返回该字面量地址;而如果该字面量已经存在于全局字符串常量池中,那么将不会进行任何操作,返回的对象就是该方法接收者本身。这一点我们通过查看该方法的源码上的注释得以理解:
|
|
总结
本文主要对常量池进行了更加详细的区分,同时增加了部分个人理解在里面,虽然简单,但是依然有几条比较重要的观点需要记录:
- 全局字符串常量池在每一个虚拟机中有且只有一份,保存的是字面常量的引用值。
class常量池在编译的时候是每一个类独立拥有一份,在编译阶段保存的是常量的符号引用。- 运行时常量池是在类加载阶段完成之后,将每一个
class常量池中的符号引用转换成直接引用之后保存到运行时常量池中的,所以每一个类都具有一个独立的运行时常量池,类在解析、将符号引用替换成直接引用之后,直接引用的值就是全局字符串常量池中保存的值。