序
近期想着设计一款下载工具,帮助节约平时下载时间,因而需要深入研究IO这块知识,虽然之前一直有研究过这块知识,但是一直没有去记录,所以这次研究之后便有了这篇文章。
本文主要想讲述IO和NIO中的文件操作部分,从源码级别比较一下这两种实现方式的不同,同时引申一下关于使用堆外内存的方式加速文件操作,提升文件读写速率。
传统IO操作文件
stream:流,简单来说就是建立在面向对象基础上的一种抽象的处理数据的工具。在流中,定义了一些处理数据的基本操作,如读取数据、写入数据,程序员对流进行所有操作,而不需要去关心流的另一头数据的真正流向。
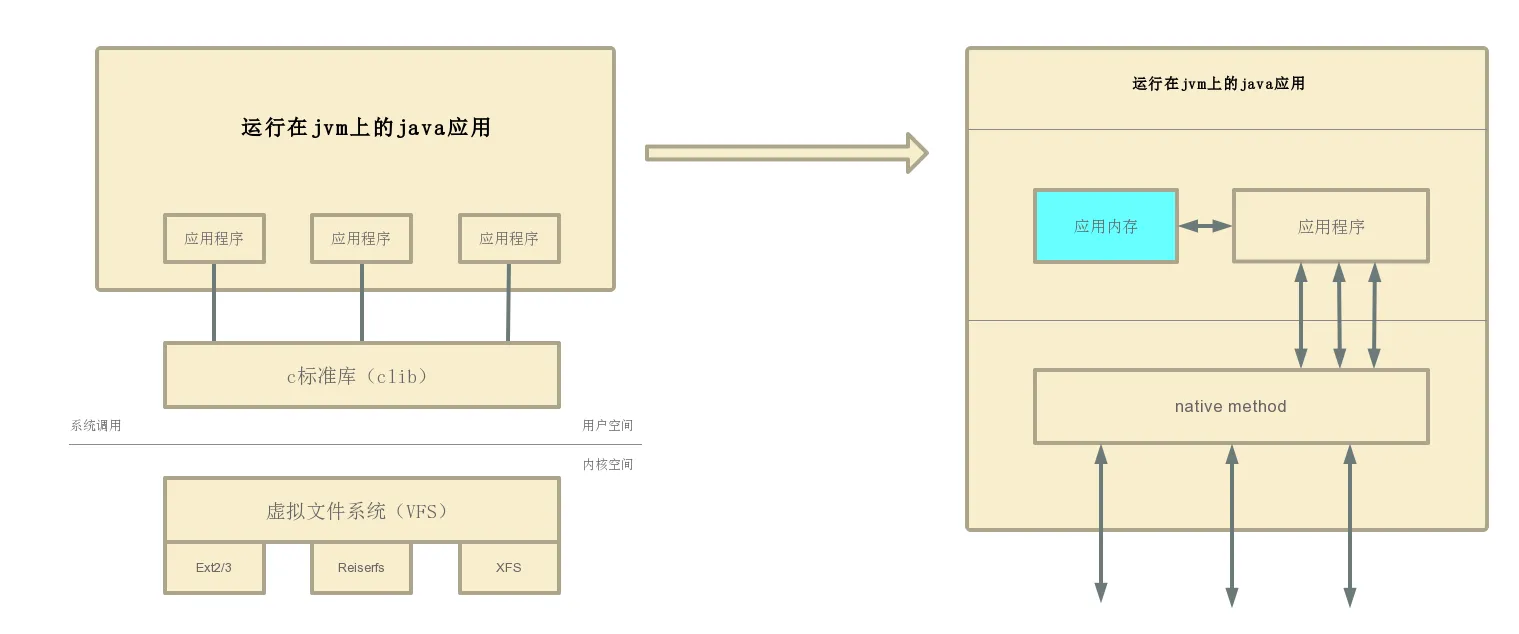
其实就是针对文件操作的一种抽象化定义,每一种语言中都有其自己定义的流的方式,但是在java中主要的不同是,java是运行在java虚拟机中的,依托jvm来运行的。所以java中不可能把整个文件的数据全部加载到虚拟机内存中,这样很容易出现问题,因而基本逻辑应该是:java应用和虚拟机进行交互,虚拟机和操作系统交互,操作系统去该读取的地方读取数据然后再原路返回给java用用层面,完成一次的文件读取。基本流程如下:
java应用程序读取文件流程
文件读取流程.png InputStream是一个抽象类,表示所有字节输入流实现类的基类。它的作用是定义了一系列从不同数据源获取操作数据的方法,具体的方法实现由其子类进行,常见子类如FileInputStream、FilterInputStream。下面我们来看一下InputStream类的源码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
/**
* 所有字节输入流的基类
*/
public abstract class InputStream implements Closeable {
/**
* 缓冲字节数据的最大值
*/
private static final int MAX_SKIP_BUFFER_SIZE = 2048 ;
//抽象方法,用来读取数据的下一个字节,返回本次读取的字节
public abstract int read () throws IOException ;
//从输入流中读取一定量的字节数据
public int read ( byte b []) throws IOException {
return read ( b , 0 , b . length );
}
//读取最多Len长度的数据保存在数组中,数组中保存位置从off开始
public int read ( byte b [], int off , int len ) throws IOException {
if ( b == null ) {
throw new NullPointerException ();
} else if ( off < 0 || len < 0 || len > b . length - off ) {
throw new IndexOutOfBoundsException ();
} else if ( len == 0 ) {
return 0 ;
}
int c = read ();
if ( c == - 1 ) {
return - 1 ;
}
b [ off ] = ( byte ) c ;
int i = 1 ;
try {
for (; i < len ; i ++) {
c = read ();
if ( c == - 1 ) {
break ;
}
b [ off + i ] = ( byte ) c ;
}
} catch ( IOException ee ) {
}
return i ;
}
//跳过输入流中的n个字节
public long skip ( long n ) throws IOException {
long remaining = n ;
int nr ;
if ( n <= 0 ) {
return 0 ;
}
int size = ( int ) Math . min ( MAX_SKIP_BUFFER_SIZE , remaining );
byte [] skipBuffer = new byte [ size ];
while ( remaining > 0 ) {
nr = read ( skipBuffer , 0 , ( int ) Math . min ( size , remaining ));
if ( nr < 0 ) {
break ;
}
remaining -= nr ;
}
return n - remaining ;
}
//返回下一次不受阻塞地从输入流中读取数据的字节数
public int available () throws IOException {
return 0 ;
}
//关闭输入流,同时释放相关资源
public void close () throws IOException {}
//标记当前读取到的输入流位置,便于重新读取上一次读取的数据
public synchronized void mark ( int readlimit ) {}
//重新定位到最后以一次对此输入流调用mark方法时的位置
public synchronized void reset () throws IOException {
throw new IOException ( "mark/reset not supported" );
}
//判断该输入流是否支持mark()和reset()
public boolean markSupported () {
return false ;
}
}
Copy 在上面的代码中,我们可以看到几个问题。首先,read方法有着很重要的作用,read(byte b[])方法内部调用的是read(byte b[], int off, int len)方法,而read(byte b[], int off, int len)方法中主要做的事情便是循环调用read()方法,达到读取指定长度的数据到数组中;其次,read()方法是一个十分重要的抽象方法,任何继承该基类的子类都需要实现该方法,该方法主要的功能是要求每一次都读取一个字节长度的数据,同时返回读取成功之后的字节标记位置。read()方法仅仅要求了功能,并没有限制子类的实现方式,给了子类很大的自由。
其实InputStream类是一个比较简单的类,并没有十分复杂的逻辑在里面,我们可以轻易的了解其逻辑,所以也看到了一个很明显的弊端:我们读取指定字节的数据到数组中,需要重复调用read()方法多次,这样效率便低了下来,并不适合数据很大的操作。
我们知道,InputStream类效率并不高,每当我们在外部进行一次读操作的时候,其内部可能需要调用read()方法多次,要知道,这样的一系列的操作都是串行的,没有合理的利用计算机的并行操作,必然导致效率十分底下。为此,BufferedInputStream类应运而生。
BufferedInputStream,名如其功能,它主要提供了一个缓冲的平台,让原本每一次执行read操作的时候都需要去调用一次底层的方法,变成了不需要每一次都去调用底层方法,相对原本的操作来说已经很大程度上提高了效率。下面我们来看看它为何可以拥有这种神奇的功能。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
222
223
224
225
226
227
228
229
230
231
232
233
234
235
public class BufferedInputStream extends FilterInputStream {
//默认缓冲空间大小
private static int DEFAULT_BUFFER_SIZE = 8192 ;
//允许最大的缓冲空间大小
private static int MAX_BUFFER_SIZE = Integer . MAX_VALUE - 8 ;
//获取Unsafe实例,该类是一个可以操作指针的类,比较危险
private static final Unsafe U = Unsafe . getUnsafe ();
//获取该对象的属性在内存中相对于该对象的偏移量,这样便可以依据该偏移量在内存中找到该属性
private static final long BUF_OFFSET
= U . objectFieldOffset ( BufferedInputStream . class , "buf" );
//存储数据的内部缓冲区,缓冲的数据保存在这里
protected volatile byte [] buf ;
//【缓冲区】可读的字节数量,count<=pos表明缓冲区内容已经读完,可以再次填充
protected int count ;
//【缓冲区】中当前读取的位置,下一个要读取字节的缓冲数组下标
protected int pos ;
//重复读取时标记的位置
protected int markpos = - 1 ;
//当用户调用了mark(int marklimit)方法以后,接着可以读取marklimit个字节,reset方法依然有效
protected int marklimit ;
private InputStream getInIfOpen () throws IOException {
InputStream input = in ;
if ( input == null )
throw new IOException ( "Stream closed" );
return input ;
}
private byte [] getBufIfOpen () throws IOException {
byte [] buffer = buf ;
if ( buffer == null )
throw new IOException ( "Stream closed" );
return buffer ;
}
public BufferedInputStream ( InputStream in ) {
this ( in , DEFAULT_BUFFER_SIZE );
}
public BufferedInputStream ( InputStream in , int size ) {
super ( in );
if ( size <= 0 ) {
throw new IllegalArgumentException ( "Buffer size <= 0" );
}
buf = new byte [ size ];
}
/*
* 填充缓冲数组
*/
private void fill () throws IOException {
byte [] buffer = getBufIfOpen ();
//没有标记位置,直接将当前位置设置为0,丢弃所有缓冲数组里的旧数据
if ( markpos < 0 )
pos = 0 ;
//缓冲数组已经被读完
else if ( pos >= buffer . length )
//标记位置有效,丢弃0到markpos之间(不包含markpos)的数据,并将剩余字节前移
//记住这里并没有真正去清楚缓冲数组数据,而是通过标志位的方式进行丢弃,所有的存储工作都是和标志位关联
if ( markpos > 0 ) {
int sz = pos - markpos ;
System . arraycopy ( buffer , markpos , buffer , 0 , sz );
pos = sz ;
markpos = 0 ;
//该条件下pos-markpos 已经大于等于marklimit 表示该mark已经失效,丢弃缓冲区中的所有数据
} else if ( buffer . length >= marklimit ) {
markpos = - 1 ;
pos = 0 ;
} else if ( buffer . length >= MAX_BUFFER_SIZE ) {
throw new OutOfMemoryError ( "Required array size too large" );
} else { //原缓冲区已经读完,但是markpos未失效,则重新创建一个更大的缓冲数组,
// 并将旧数组的数据拷贝到新数组
int nsz = ( pos <= MAX_BUFFER_SIZE - pos ) ?
pos * 2 : MAX_BUFFER_SIZE ;
if ( nsz > marklimit )
nsz = marklimit ;
byte [] nbuf = new byte [ nsz ];
System . arraycopy ( buffer , 0 , nbuf , 0 , pos );
if (! U . compareAndSetObject ( this , BUF_OFFSET , buffer , nbuf )) {
throw new IOException ( "Stream closed" );
}
buffer = nbuf ;
}
count = pos ;
//读取数据到缓冲区
int n = getInIfOpen (). read ( buffer , pos , buffer . length - pos );
if ( n > 0 )
count = n + pos ;
}
public synchronized int read () throws IOException {
//缓冲区中的数据已经读取完毕,需要重新加载数据进缓冲区
if ( pos >= count ) {
fill ();
if ( pos >= count )
return - 1 ;
}
//从缓冲区中读取一个字节
//因为byte字节转int会带符号,所以需要通过&0xff将int的高24位置0
return getBufIfOpen ()[ pos ++] & 0xff ;
}
private int read1 ( byte [] b , int off , int len ) throws IOException {
int avail = count - pos ;
//小于等于0说明缓冲区里面的数据已经全部读完,需要重新加载
if ( avail <= 0 ) {
//如果要读取的字节数大于等于缓冲区数组大小,并且markpos无效,则跳过缓冲区直接读取
if ( len >= getBufIfOpen (). length && markpos < 0 ) {
return getInIfOpen (). read ( b , off , len );
}
fill ();
avail = count - pos ;
if ( avail <= 0 ) return - 1 ;
}
//确定能够从缓冲区读取的数据数量,可能可以全部从缓冲区读,可能可以部分从缓冲区读
int cnt = ( avail < len ) ? avail : len ;
System . arraycopy ( getBufIfOpen (), pos , b , off , cnt );
pos += cnt ;
return cnt ;
}
public synchronized int read ( byte b [], int off , int len )
throws IOException
{
getBufIfOpen (); // Check for closed stream
if (( off | len | ( off + len ) | ( b . length - ( off + len ))) < 0 ) {
throw new IndexOutOfBoundsException ();
} else if ( len == 0 ) {
return 0 ;
}
int n = 0 ;
for (;;) {
//死循环式读取,确保可以读取完指定数量的数据
int nread = read1 ( b , off + n , len - n );
if ( nread <= 0 )
return ( n == 0 ) ? nread : n ;
n += nread ;
if ( n >= len )
return n ;
// if not closed but no bytes available, return
InputStream input = in ;
if ( input != null && input . available () <= 0 )
return n ;
}
}
public synchronized long skip ( long n ) throws IOException {
getBufIfOpen (); // Check for closed stream
if ( n <= 0 ) {
return 0 ;
}
long avail = count - pos ;
if ( avail <= 0 ) {
// If no mark position set then don't keep in buffer
if ( markpos < 0 )
return getInIfOpen (). skip ( n );
// Fill in buffer to save bytes for reset
fill ();
avail = count - pos ;
if ( avail <= 0 )
return 0 ;
}
long skipped = ( avail < n ) ? avail : n ;
pos += skipped ;
return skipped ;
}
public synchronized int available () throws IOException {
int n = count - pos ;
int avail = getInIfOpen (). available ();
return n > ( Integer . MAX_VALUE - avail )
? Integer . MAX_VALUE
: n + avail ;
}
public synchronized void mark ( int readlimit ) {
marklimit = readlimit ;
markpos = pos ;
}
public synchronized void reset () throws IOException {
getBufIfOpen (); // Cause exception if closed
if ( markpos < 0 )
throw new IOException ( "Resetting to invalid mark" );
pos = markpos ;
}
public boolean markSupported () {
return true ;
}
public void close () throws IOException {
byte [] buffer ;
while ( ( buffer = buf ) != null ) {
if ( U . compareAndSetObject ( this , BUF_OFFSET , buffer , null )) {
InputStream input = in ;
in = null ;
if ( input != null )
input . close ();
return ;
}
// Else retry in case a new buf was CASed in fill()
}
}
}
Copy 简单分析一下BufferedInputStream,在该类中维护了一个字节数组buf[],专门用来缓存InputStream中read方法读取的数据,这样可以保证在一次请求的时候可以从磁盘空间中读取足够多的数据,而后续线程获取数据的时候也不再需要每一次都向底层发送请求 - -直接从buf中拿数据即可。我们知道,与底层的通信往往伴随着创建 、传输 、销毁 等过程,而减少针对底层的访问,实际上便提高了数据交互的效率。
的确像BufferedInputStream相关的缓冲类针对磁盘读写效率有了很大的提高,但是这其实还是比较低效的,毕竟这个和底层交互的过程并没有很大程度上地减少,仅仅是一定程度上地减少了针对底层的调用次数,类似InputStream的read方法依然存在。所以需要完全摒弃这种做法,从另外一个层面上去考虑数据读取才是硬道理。
NIO操作文件
Channel&Buffer
Channel(通道)和Buffer(缓冲区)是NIO中的核心对象,几乎每一个I/O都在操作它们。
通道是对原I/O中的流的模拟。到任何目的地(或来自任何地方)的所有数据都必须通过Channel对象。一个Buffer实际上是一个容器对象,发送给一个通道的所有对象都必须首先放到缓冲区中;同样地,从通道中读取的任何数据都要读到缓冲区中。
常用的Channel主要有
FileChannel:文件操作通道DatagramChannel:UDP操作通道SocketChannel:TCP操作ServerSocketChannel:TCP操作,使用在服务端
最常用的缓冲区类型是ByteBuffer。一个ByteBuffer可以在其底层字节数组上进行get/set操作(即字节的获取和设置),ByteBuffer并不是NIO中唯一的缓冲区类型,事实上,对于每一种Java类型都有一种缓冲区类型:
ByteBufferCharBufferShortBufferIntBufferLongBufferFloatBufferDoubleBuffer
每一个Buffer类都是Buffer接口的一个实例。除了ByteBuffer,每一个Buffer类都有完全一样的操作,只是它们所处理的数据类型不一样。因为大多数标准I/O操作都是使用ByteBuffer,所以它具有所有共享的缓冲区操作以及一些特有的操作。
ByteBuffer
在阅读ByteBuffer源码之前,我们先看看Buffer类中几个重要的属性以及方法
Buffer
Buffer常用变量
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
/**
* 临时备忘位置变量,调用mark()方法的话,mark值将会存储当前position的值,
* 等下次调用reset()方法时,会设定position的值为之前的mark值
*/
private int mark = - 1 ;
/**
* 下一个要被读写的元素的数组下标索引,该值会随着get()和put()的调用自动更新
*/
private int position = 0 ;
/**
* 缓冲区可读可写的容量,可读可写limit最大情况下,limit=capacity
* 读条件下:总共拥有多少数据可以被读,强调数据量(强调已占用容量)
* 写条件下:总共拥有多少空间可以被写,强调写空间的总共大小(强调总共容量)
*/
private int limit ;
/**
* 缓冲区的能够容纳元素的最大数量,该值在缓冲区创建时被设定
*/
private int capacity ;
//指向缓冲区的地址
long address ;
Copy 如果想详细了解可以参考下面的博客:
构造方法
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
//创建一个指定mark pos limit capacity 参数的构造器
Buffer ( int mark , int pos , int lim , int cap ) {
//如果缓冲区的初始化容量小于0,那么抛出非法参数异常
if ( cap < 0 )
throw createCapacityException ( cap );
//设置缓冲区初始化容量
this . capacity = cap ;
//设置缓冲区的限制,设置最新的缓冲区
limit ( lim );
position ( pos );
if ( mark >= 0 ) {
if ( mark > pos )
throw new IllegalArgumentException ( "mark > position: ("
+ mark + " > " + pos + ")" );
this . mark = mark ;
}
}
Copy
limit方法:设置缓冲区的限制
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
/**
* 设置缓冲区的限制
* 如果position>limit 那么重新设置成新的limit
* 如果mark>limit 那么最新的limit将会被抛弃
*/
public Buffer limit ( int newLimit ) {
//可读些容量异常
if ( newLimit > capacity | newLimit < 0 )
throw createLimitException ( newLimit );
//设置最新的可读写容量
limit = newLimit ;
//可读写位置大于可读写容量,说明已经没有可读写空间
if ( position > limit ) position = limit ;
//标记位置超出可读写容量
if ( mark > limit ) mark = - 1 ;
return this ;
}
Copy
position方法:设置读写开始的位置
1
2
3
4
5
6
7
8
9
10
11
12
13
/**
* 设置读写的开始位置,如果mark>position,那么position这个变量将会被抛弃
*/
public Buffer position ( int newPosition ) {
//如果输入的newPosition大于可读写的最大容量或者newPosition小于0,那么将抛出非法异常参数
if ( newPosition > limit | newPosition < 0 )
throw createPositionException ( newPosition );
//设置输入参数newPosition作为最新的读写开始位置
position = newPosition ;
//如果临时备忘录位置mark大于position,设置mark为-1
if ( mark > position ) mark = - 1 ;
return this ;
}
Copy
flip()方法
1
2
3
4
5
6
7
8
9
10
11
12
13
14
/**
* 反转此缓冲区
* 在进行写完去读的时候使用
*/
public final Buffer flip () {
//将读写的最大容量设置为当前的位置
limit = position ;
//将position设置为0
position = 0 ;
//设置临时备忘变量为-1
mark = - 1 ;
//返回当前最新的缓冲区Buffer
return this ;
}
Copy
rewind()方法
1
2
3
4
5
6
7
8
9
10
11
12
/**
* 重绕此缓冲区
* 在通道写入或者获取之前调用
*/
public final Buffer rewind () {
//设置当前位置为0
position = 0 ;
//将临时备忘变量设置为-1
mark = - 1 ;
//返回当前最新的缓冲区Buffer
return this ;
}
Copy ByteBuffer
作为Buffer的子类,ByteBuffer中的大部分方法都是继承了它的父类方法,同时在父类的基础上,它还添加了自己的方法。
接下来,我们看看ByteBuffer类中是怎样创建相关Buffer的
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
public abstract class ByteBuffer
extends Buffer
implements Comparable < ByteBuffer >
{
final byte [] hb ;
final int offset ;
boolean isReadOnly ;
ByteBuffer ( int mark , int pos , int lim , int cap ,
byte [] hb , int offset )
{
super ( mark , pos , lim , cap );
this . hb = hb ;
this . offset = offset ;
}
ByteBuffer ( int mark , int pos , int lim , int cap ) {
this ( mark , pos , lim , cap , null , 0 );
}
/**
* 创建基于堆外内存的ByteBuffer,使用的是默认缓冲区
*/
public static ByteBuffer allocateDirect ( int capacity ) {
return new DirectByteBuffer ( capacity );
}
/**
* 创建基于堆内内存的ByteBuffer,使用的是默认缓冲区
*/
public static ByteBuffer allocate ( int capacity ) {
if ( capacity < 0 )
throw createCapacityException ( capacity );
return new HeapByteBuffer ( capacity , capacity );
}
/**
* 创建堆外内存的ByteBuffer,使用的缓冲区是外部传入的,重载方法
*/
public static ByteBuffer wrap ( byte [] array ,
int offset , int length )
{
try {
return new HeapByteBuffer ( array , offset , length );
} catch ( IllegalArgumentException x ) {
throw new IndexOutOfBoundsException ();
}
}
/**
* 创建堆外内存的ByteBuffer,使用的缓冲区是外部传入的
* @param array
* @return
*/
public static ByteBuffer wrap ( byte [] array ) {
return wrap ( array , 0 , array . length );
}
}
Copy 很遗憾,在ByteBuffer类中并没有直接地去创建相关Buffer,而是通过不同的创建方式,交给了两个子类HeapByteBuffer和DirectByteBuffer来实现,以及进行相关的数据读写操作,也就是说,这两个类分别使用不同的底层方式针对数据进行了读写操作。考虑到文章篇幅,我决定将其单独独立出来作为一篇文章进行讲述,有兴趣可以看一下我的另一篇文章:ByteBuffer深层探秘,了解底层实现原理
总结
NIO中的Buffer类和BufferedInputStream有一点相似的地方是,都是通过读取数据到一个缓冲区,同时通过控制缓冲区的索引,来控制数据的读写操作。虽然两种方式都拥有一个缓冲区,但是其实拥有着很大的不同,在Stream(流)中,针对读和写的操作需要提供两个不相关的类(Input和Output)来实现,但是在Buffer中,数据的读写都是在同一个Buffer中,从外部来看简化了普通使用者的操作,同时实现逻辑也变得更加复杂。
Buffer中在每一个读或者写之前需要注意切换读写方式(其实就是通过设置一些标志位,让其记录读写时每一次操作Buffer的位置)。在写完去读的时候,使用flip方法,特点是将读的容量limit设置为写的position,将读的开始位置position设置为0,将mark设置为-1。
在读完去写的时候,使用clear方法,特点是将position设置为0,写的limit值设置为当前缓冲区的capacity,将mark设置为-1。
FileChannel
一般称作管道,其实就是一个操作Buffer的类,具体进行文件读写的操作还是放在Buffer中进行的。FileChannel是一个文件管道,主要用来读写文件的,该抽象类中仅仅定义了一些read和write操作的抽象方法,具体实现类是FileChannelImpl。下面我们来看看FileChannelImpl这个类。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
// Used by FileInputStream.getChannel(), FileOutputStream.getChannel
// and RandomAccessFile.getChannel()
//从这里我们知道了创建FileChannel的几种方式
public static FileChannel open ( FileDescriptor fd , String path ,
boolean readable , boolean writable ,
boolean direct , Object parent )
{
return new FileChannelImpl ( fd , path , readable , writable , direct , parent );
}
//从文件读取数据到缓冲区
public long read ( ByteBuffer [] dsts , int offset , int length ) throws IOException {
if (( offset < 0 ) || ( length < 0 ) || ( offset > dsts . length - length ))
throw new IndexOutOfBoundsException ();
ensureOpen ();
if (! readable ) //在读的方法中不可读直接抛异常
throw new NonReadableChannelException ();
//线程安全
synchronized ( positionLock ) {
//DirectIO 不使用操作系统缓冲,使得磁盘IO(或者DMA)直接将数据存入用户空间的buffer。
//避免内核缓冲的内存消耗与CPU拷贝(数据从内核空间到用户空间的拷贝)的消耗。
//即我们所说的使用堆外内存方式,创建的DirectByteBuffer
if ( direct )
Util . checkChannelPositionAligned ( position (), alignment );
long n = 0 ;
int ti = - 1 ;
try {
//标志着可能无限期阻塞的I/O操作的开始
begin ();
//添加当前的原生线程到集合,然后该线程在集合中的索引,以便之后可以高效移除它
ti = threads . add ();
if (! isOpen ())
return 0 ;
do {
//读取文件数据到buffer
n = IOUtil . read ( fd , dsts , offset , length ,
direct , alignment , nd );
} while (( n == IOStatus . INTERRUPTED ) && isOpen ());
return IOStatus . normalize ( n );
} finally {
threads . remove ( ti );
//标志着该操作的结束
end ( n > 0 );
assert IOStatus . check ( n );
}
}
}
//从缓冲区写数据到文件
public long write ( ByteBuffer [] srcs , int offset , int length ) throws IOException {
if (( offset < 0 ) || ( length < 0 ) || ( offset > srcs . length - length ))
throw new IndexOutOfBoundsException ();
ensureOpen ();
if (! writable ) //在写的方法中不可写,直接抛异常
throw new NonWritableChannelException ();
//线程安全
synchronized ( positionLock ) {
if ( direct )
Util . checkChannelPositionAligned ( position (), alignment );
long n = 0 ;
int ti = - 1 ;
try {
begin ();
ti = threads . add ();
if (! isOpen ())
return 0 ;
do {
//将buffer数据写入新的文件中
n = IOUtil . write ( fd , srcs , offset , length ,
direct , alignment , nd );
} while (( n == IOStatus . INTERRUPTED ) && isOpen ());
return IOStatus . normalize ( n );
} finally {
threads . remove ( ti );
end ( n > 0 );
assert IOStatus . check ( n );
}
}
}
Copy 从上面的代码中,我们可以看到在FileChannel中仅仅起到了一个调度和控制的作用,真正针对Buffer的调用还不在这里进行。我们需要深入到IOStatus类中进行查看。
read方法
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
static int read ( FileDescriptor fd , ByteBuffer dst , long position ,
boolean directIO , int alignment , NativeDispatcher nd )
throws IOException
{
//如果是只读的,那么不适用,直接抛异常
if ( dst . isReadOnly ())
throw new IllegalArgumentException ( "Read-only buffer" );
//如果显示地声明了该缓冲区是一个DirectIO那么直接去调用readIntoNativeBuffer方法,
//执行读取文件到缓冲区操作
if ( dst instanceof DirectBuffer )
return readIntoNativeBuffer ( fd , dst , position ,
directIO , alignment , nd );
// Substitute a native buffer
ByteBuffer bb ;
//返回在position和limit之间的可用空间大小
int rem = dst . remaining ();
//如果想创建一个DirectBuffer那么使用该方式创建
if ( directIO ) {
//DirectIO需要一个连续的内存空间进行存储,所以这里判断目标空间是否够用
Util . checkRemainingBufferSizeAligned ( rem , alignment );
//创建一个DirectBuffer
bb = Util . getTemporaryAlignedDirectBuffer ( rem ,
alignment );
} else {
//依据目标文件大小创建Buffer类型,如果文件很大,那么需要创建DirectBuffer,否则创建目标类型的Buffer
bb = Util . getTemporaryDirectBuffer ( rem );
}
try {
//执行读取文件到Buffer操作,返回下一次读取位置
int n = readIntoNativeBuffer ( fd , bb , position ,
directIO , alignment , nd );
//切换Buffer状态
bb . flip ();
if ( n > 0 )
//复制数据到src的Buffer中
dst . put ( bb );
return n ;
} finally {
//将局部变量Buffer保存到缓存或者直接释放
Util . offerFirstTemporaryDirectBuffer ( bb );
}
}
private static int readIntoNativeBuffer ( FileDescriptor fd , ByteBuffer bb ,
long position , boolean directIO ,
int alignment , NativeDispatcher nd )
throws IOException
{
int pos = bb . position ();
int lim = bb . limit ();
assert ( pos <= lim );
int rem = ( pos <= lim ? lim - pos : 0 );
if ( directIO ) { //检查相关空间是否够用,不够用直接抛异常
Util . checkBufferPositionAligned ( bb , pos , alignment );
Util . checkRemainingBufferSizeAligned ( rem , alignment );
}
if ( rem == 0 )
return 0 ;
int n = 0 ;
if ( position != - 1 ) { //这里通过position是否为-1来调用底层不同的native方法,执行read操作
n = nd . pread ( fd , (( DirectBuffer ) bb ). address () + pos ,
rem , position );
} else {
n = nd . read ( fd , (( DirectBuffer ) bb ). address () + pos , rem );
}
if ( n > 0 )
bb . position ( pos + n );
return n ;
}
Copy 堆外内存
参考