
前情提要
在学习迭代器模式时想到的一些问题文章结束的时候,我有留一个问题,问的是mvcc的原理,以及mvcc和CopyOnWrite的一些异同点,那么今天我就来聊一聊关于mvcc的一些话题。
MVCC
MVCC,多版本并发控制(Mutil-Version Concurrency Control),基本可以认为它是行锁的一个变种,但是它在很多情况下避免了加锁操作,因此开销更低,其主要实现方式和我们上一篇介绍的CopyOnWrite原理相似,都是通过在更改数据的时候,不直接在原数据上进行更改,而是通过针对预先“复制“的一份副本进行修改,而读数据时,是直接读取原始版本数据,这样来保证读取数据的事务不会因为其他事务对数据的修改,而发生一个事务周期内读取数据不同的情况。
虽然MVCC和CopyOnWrite在某些程度上是相似的,但是它们还是存在很大区别的,不然也不会去给它一个单独的名称,所以我们还是来看看MVCC的原理,看看它究竟是如何实现的。
原理
示例
先来看一个例子:
例子来源《MySQL实战45讲》第08讲
|
|

说明:图中start transaction with consistent snapshot表示立即开启一个事务,而一般的像begin/start transaction都是等到真正执行这条sql的时候才会去启动事务;图中的事务,默认autocommit=1。
先来说一下结果,事务A查询结果为1,事务B查询结果为3。
原理分析
InnoDB的MVCC中,会在每一张数据表的最后增加两列,分别叫做DATA_TRX_ID和DATA_ROLL_PTR,其中DATA_TRX_ID用来记录当前修改这一行数据的事务ID,而DATA_ROLL_PTR用来记录该行的上一个历史版本位置。
这样表中的一行记录,很有可能会存在多个版本,大概如图所示:
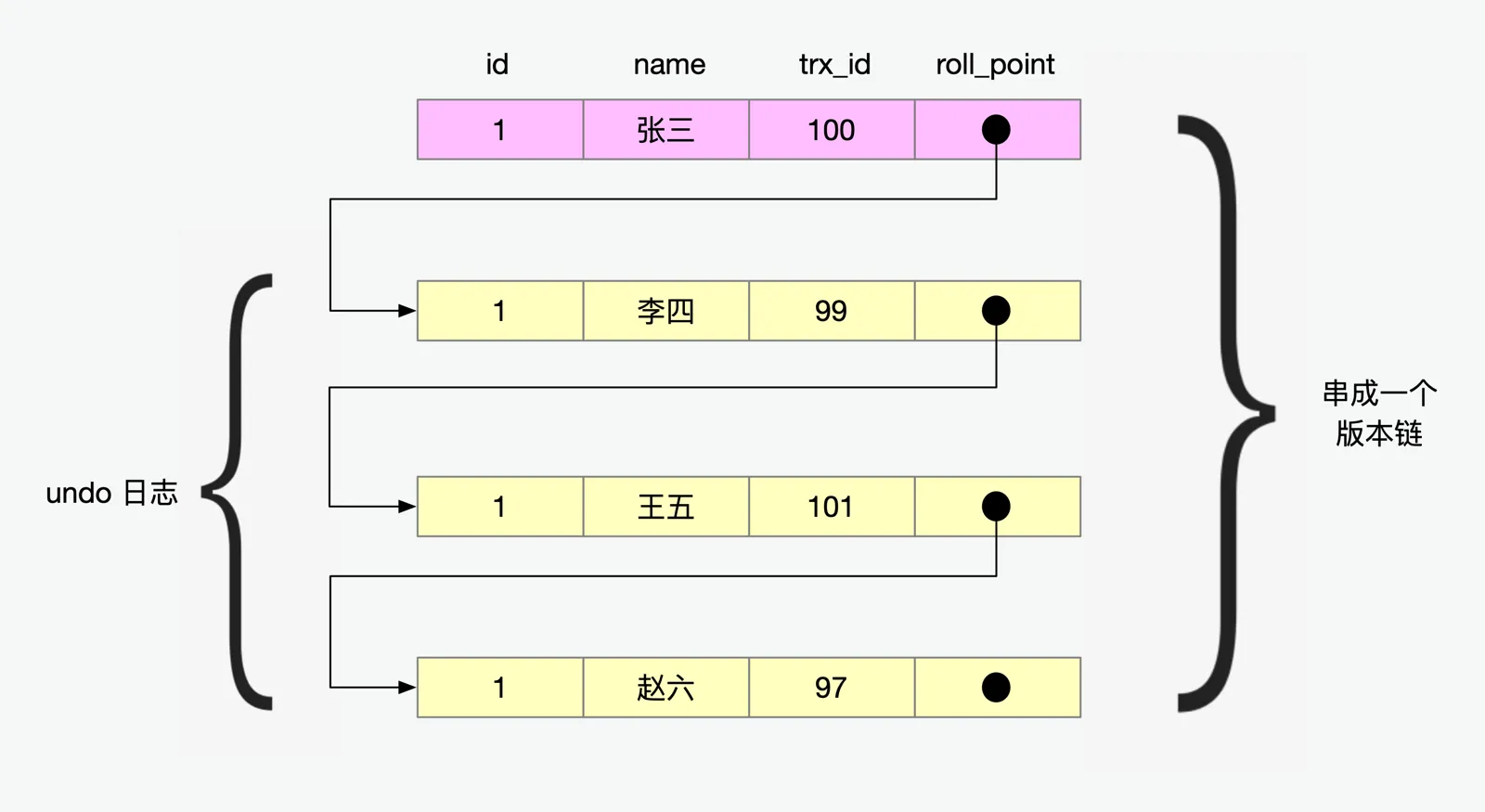
图中针对id为1的这一行记录,在某个事务开启时可以看到这条记录目前存在四个版本,每个版本存在着其自己的trx_id,trx_id保存的对应的值就是哪个事务创建的数据版本。
所有版本通过链表串联成一个版本链,每一个版本的前面的版本就是当前版本的undo log(注意:每一个版本并非一定可以看到它前面的所有版本,例如trx_id为99的就看不到它前面trx_id为101的版本数据,至于为什么,后面会提到),这样当一个事务进行回滚的时候,就可以按照undo log进行回滚到最近的版本。
因为记录有了版本,所以当一个新的事务开启的时候,只需要声明从当前事务开启的时刻起,如果一个数据记录的版本是当前事务开启之前创建的,那么当前事务就可以看到,如果是之后创建的,那么就不能看到,也就必须要依据版本链找到一个它能够看到的记录版本,这样的一个概念其实就是一致性视图(READ VIEW)。
那么一致性视图是如何实现的呢?我们继续往下看。
在实现上,InnoDB为每一个事务创建了一个用来保存这个事务启动瞬间当前活跃的事务的集合。也就是事务启动了,但是事务还没有提交。
集合里面事务 ID 的最小值记为低水位,当前系统里面已经创建过的事务 ID 的最大值加 1 记为高水位。这个视图数组和高水位,就组成了当前事务的一致性视图(READ VIEW)。
所以在事务启动的瞬间,一个数据的版本会存在以下几种情况:
-
如果被访问版本的
trx_id属性值小于集合中最小的事务id(小于低水位),表明生成该版本的事务在生成一致性视图前已经提交,所以该版本可以被当前事务访问。 -
如果被访问版本的
trx_id属性值大于集合中最大的事务id(大于高水位),表明生成该版本的事务在生成ReadView后才生成,所以该版本不可以被当前事务访问。 -
如果被访问版本的
trx_id属性值在集合中最大的事务id和最小事务id之间,那就需要判断一下trx_id属性值是不是在集合 中,如果在,说明创建READ VIEW时生成该版本的事务还是活跃的,该版本不可以被访问;如果不在,说明创建ReadView时生成该版本的事务已经被提交,该版本可以被访问。
问题分析
有了上面的原理作为支撑,下面我们来分析分析为何事务A得到的值是1,而事务B查询到的是3。
假设事务A在启动事务之前,当前系统中只有一个存活的事务,而且系统中后续除了已知的三个事务(A,B,C)之外,不会再创建其它事物,当前存活的事务的id为99,而事务A、事务B、事务C的id分别为100、101、102。
所以事务A中保存的活跃事务集合为[99, 100];
事务B中保存的活跃事务集合为[99, 100, 101];
事务C中保存的活跃事务集合为[99, 100, 101, 102]。
事务A、事务B、事务C启动的时刻看到的数据版本如图(因为还没有别的事务进行更改数据)
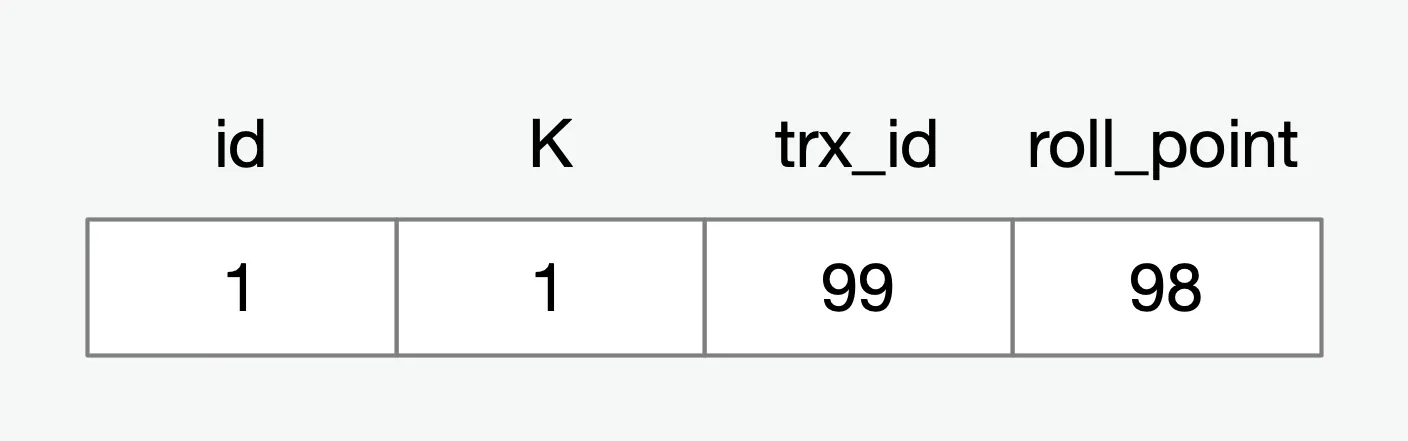
第一个有效更新是事务 C,当事务C对数据进行修改之后,这个数据的最新版本的 trx_id 是 102,而 99 这个版本已经成为了历史版本。此时改完之后,数据对应的版本如下:
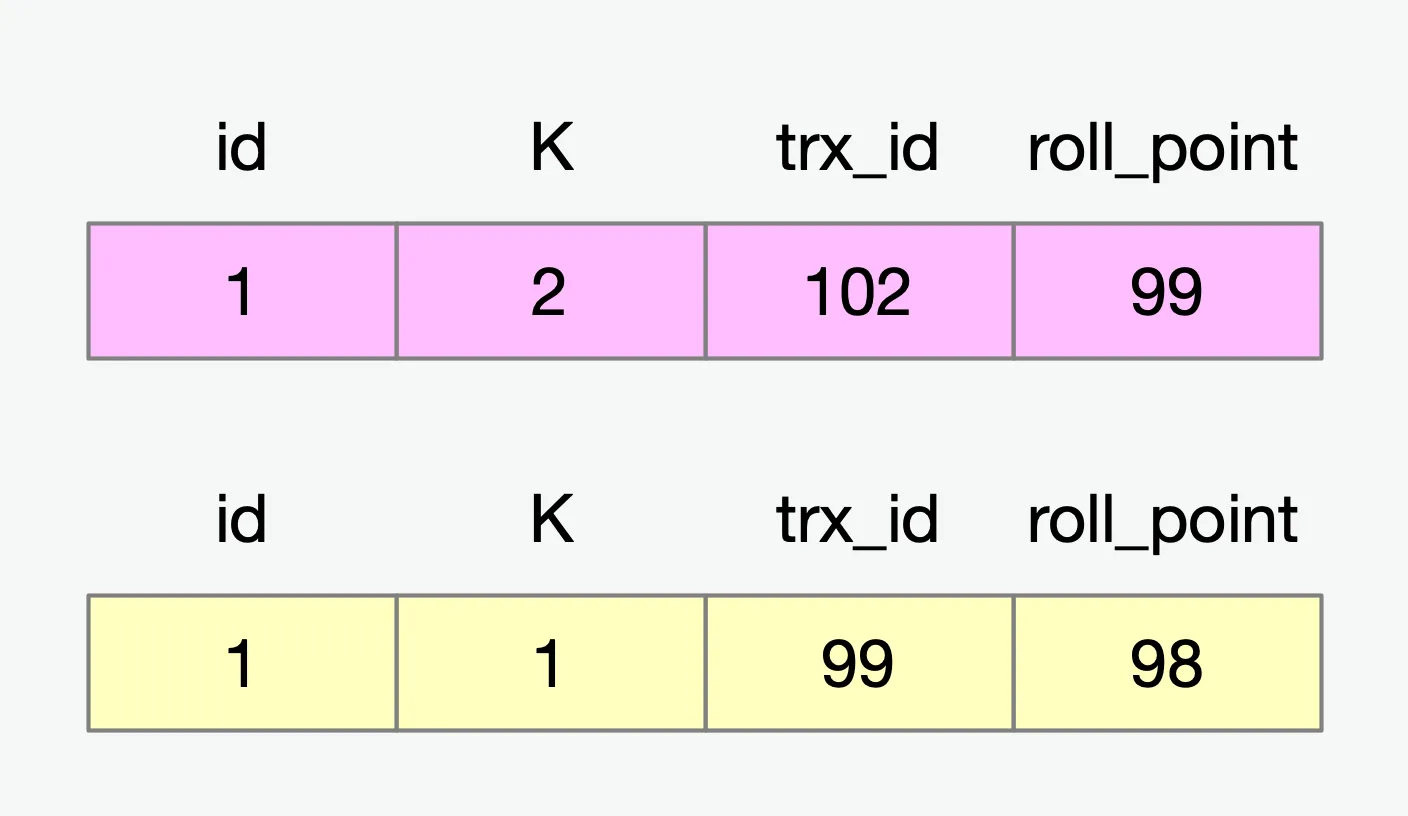
接下来事务B开始进行修改,此时如果是按照事务B中保存的活跃事务集合进行更改(因为事务B只能看到trx_id为99的哪一条),那么此时修改结束之后对应的值应该为2,然而如果这样修改,会导致事务C的修改丢失,为此又引入了另外一个概念,叫做当前读(current read)。
当前读的意思是,在对数据进行更新的时候,会先去查询最新数据,然后再对这条最新数据进行修改(修改期间会加锁),所以事务B真正修改的基础是在事务C修改之后的基础上进行的。
当事务B修改完成之后,我们可以看到目前针对id为1的数据已经存在了三个版本了:
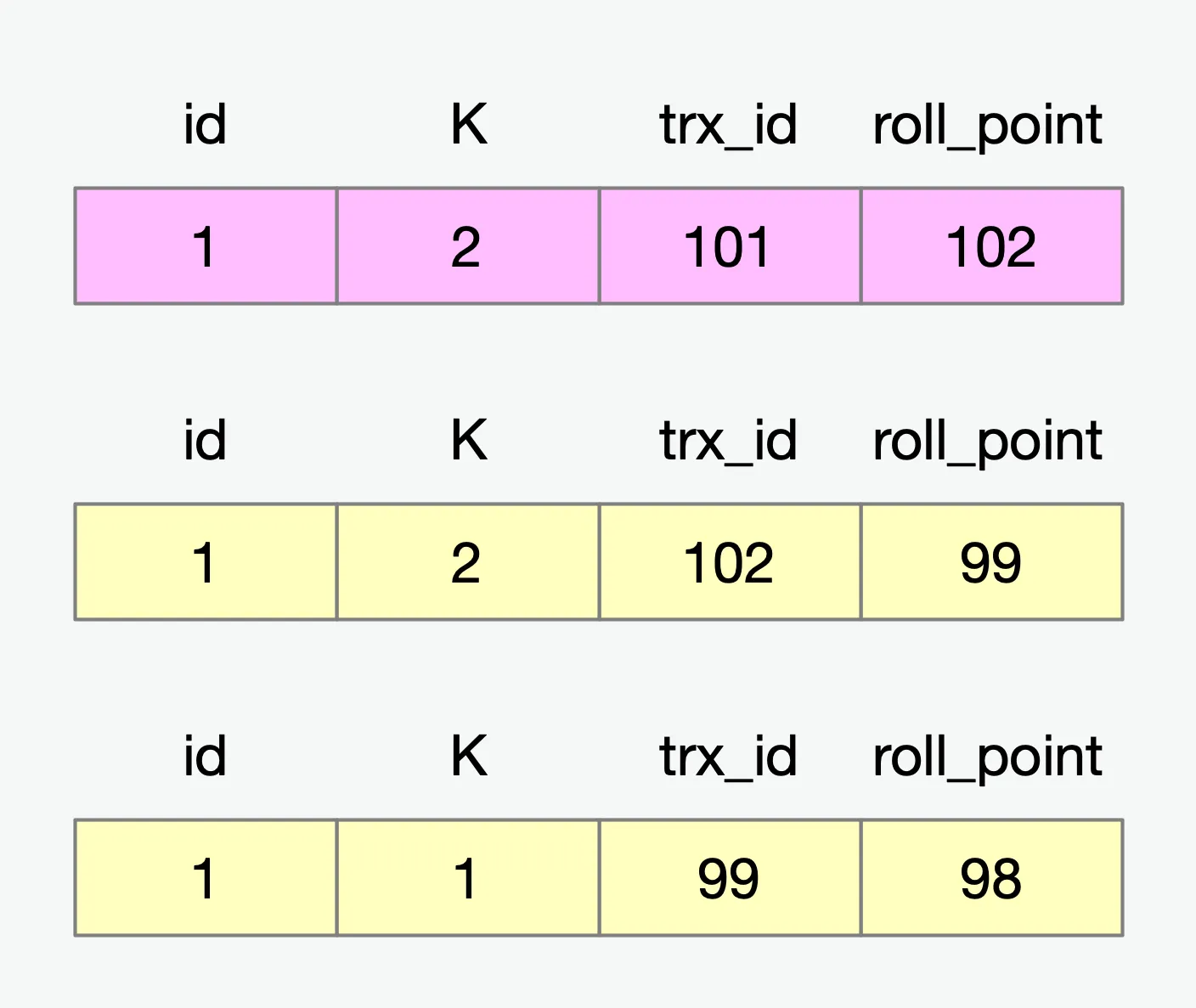
最后,事务A对应的查询语句开始工作了,因为此时事务A中对应的活跃事务集合为[99, 100],所以事务A中查询的结果是trx_id为99的数据版本。
到此,事务A和事务B的查询过程也就分析完了。
另外再说明一点,如果事务A想查询到最新的数据该怎么办?可以考虑使用当前读(通过加锁)的查询,查询语句如下:
|
|
总结
本文详细介绍了MVCC的原理和实现,其实回过头来再看的话,MVCC并没有多麻烦,无非就是给每一条操作的数据打了一个版本号,同时每一个事务在分配事务编号的时候,记录了当前事务能够看到的版本号,最后无非还利用了当前读来解决两条语句更新同一行数据的问题,整个过程清晰明朗,没有任何复杂概念在其中,最主要的还是需要多练习和分析。
参考
- 《高性能MySQL》
- 林晓斌 -《MySQL实战45讲》