
序
最近在研究高并发模型,使用redis、rabbitmq、mysql读写分离来减缓针对单数据库操作条件下数据库压力过大的问题,目前已经解决大部分问题。今天继续深入研究,思考着如果单台机器遭遇无法承受的访问量,那么该如何合理的控制多台机器针对同一数据库的操作。本问主要通过实现redis的分布式锁来解决该问题,分别从实现思想和具体代码两方面解决redis下的分布式锁问题。
遇到的问题
我们都知道,在多线程条件下访问数据库时,为了避免出现读写不一致等情况,常常使用锁的方式控制多线程修改数据库。但是,在不同机器下,这种锁的方式是起不到作用的,为此,需要使用另外的方式来解决这样的问题。
我们常使用三种方式来解决分布式条件下数据读写不一致情况,分别是:数据库表锁、redis实现分布式锁、zookeeper实现分布式锁;我们本次将通过redis来实现分布式锁,解决我们遇到的问题。
实现思想
和单机器下的锁机制一样,我们最终的目的依然是保证每一个操作数据库的线程都是“排着队”地去操作数据库,所以应该有着一个独立于整个应用的锁,当有线程需要访问操作数据库时,需要首先获取到锁,之后才能去操作数据库,也就实现了最终的读写一直性。
了解了最终实现的需求之后,我们需要思考该如何设计出这样一把独立于应用的锁。当有线程需要操作数据库的时候,我们可以将该线程的信息写入到某个公共的地方,表示该线程拥有了这把锁,可以操作数据库,而其他线程进来的时候则会先去该公共的地方去查找针对目前的操作有没有线程已经在进行,如果存在线程则阻塞等待前面的线程执行完成并释放锁,然后才会去继续获取锁。而前一个线程执行完成之后,再在公共地方把自己的信息删除掉,表示已经释放了这把锁,此时其它线程便可以继续请求获取锁和执行后续操作。
线程基本操作流程如下图
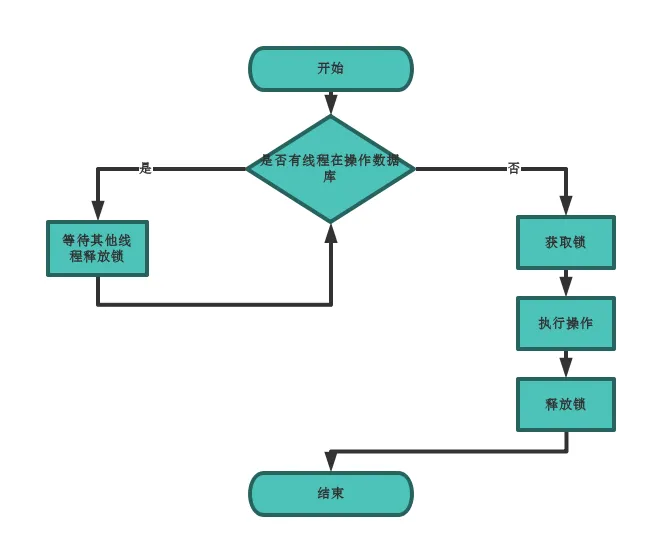
由于多线程获取锁和释放锁的过程十分频繁和短暂,因此使用传统的数据库来保存线程的信息并不是合理,所以基于内存的数据库redis在这里起到了很好的作用。
主要代码
核心操作
为了保持redis在读写操作的原子性,我们采用lua操作redis实现基本的读写和删除功能。
redis 在2.6.0之后的版本开始支持lua脚本。lua在redis使用详细见这里。在redis中执行一个lua脚本时redis会将整个脚本作为一个整体执行,中间不会被其他命令插入,解决多个命令事务的问题。
为此我们需要在java中创建两个字符串类型的常量,常量里面的内容主要是使用lua操作redis,两个常量如下:
|
|
上面四条语句中,有两条语句是针对redis操作的lua脚本,另外两条语句是针对这两条语句的封装,因此我们着重来看看两条脚本语句。
原子性添加数据
|
|
这条语句是用来保存数据进redis的,语句中有三个参数,分别为KEYS[1]、ARGV[1]、ARVG[2],除此之外还有两个我们不熟悉的参数,分别为NX和PX,下面我们来详细解释这些参数。
在redis中存在一条set命令:set key value [ex seconds] [px milliseconds] [nx|xx],该条命令中存在四个参数:
ex:为键设置秒级过期时间
px:为键设置毫秒级过期时间
nx:键必须不存在,才可以设置成功,用于添加
xx:与nx相反,键必须存在,才可以设置成功,用于更新
所以我们使用到的NX和PX十分容易理解了,主要是用来设置过期时间和设置规则的。
再来看看KEYS[1]、ARGV[1]、ARVG[2];首先这三个参数都是java中传递过来的,其中
KEYS[1]表示的是redis数据库中的键key
ARGV[1]表示的是redis数据库中的值value
ARGV表示的是redis针对px设置的毫秒级过期时间
原子性删除数据
|
|
在了解了上面的操作参数之后,这里的操作便没有我们想像的那么难以理解。上面的脚本大致做的操作便是:redis通过传入的参数key获取到redis数据库中的值value,判断和传入的参数value结果是否相等,如果相等,执行删除操作,并返回删除结果;如果结果不一致,则直接返回0。
代码实现
本文使用的redis客户端是lettuce,而非传统使用的jedis,在使用的性能上有了较大的提升,为此,我在springboot2配置中,显示地指定了redis客户端配置。
|
|
添加锁
|
|
key:保存数据进redis时,使用的key
expire:key过期时间
uuid:随机生成的一串字符串作为存储时的value
lockFlag:ThreadLocal类型的线程内局部变量
当数据成功插入到redis时会返回OK,否则返回其它结果。
释放锁
|
|
通过使用ThreadLocal类型变量,确保同一个线程获取锁和释放锁。
当redis成功删除数据的时候,会返回删除的数量即1,即代表该线程成功释放锁。
缺点
我们在实现思想中设计出的一套流程有着很多不足,例如:当有一个线程获取到锁之后,其它线程只能等待该线程释放锁之后才能获取到锁,所以其它线程要么等待该线程在锁过期之前结束任务,主动释放锁,要么等待该线程执行任务时间超过锁的过期时间。这样就会出现一系列问题。
- 如果在锁过期时间内,该线程执行任务的时间很长,那么其它线程将会等待很长时间,导致用户体验十分不好。
- 如果锁过期时间十分短暂,可能该线程获取锁之后执行的任务还没有执行完,锁便因为过期而失效,导致后序线程获取到锁,最终导致处理结果不正确。
我们这里简单使用的解决方法是针对没有获取到锁的线程,添加轮训操作,当该线程没有获取到锁之后,进入轮训阶段,轮训指定次数之后,主动退出结束本次请求,避免客户端请求一直挂载,增加服务端压力。其基本代码如下:
|
|
而针对锁过期时间太短问题,我们可以设计一个监控程序在锁周期内查看当前线程是否仍然占有锁,如果占有则延长锁的过期时间,这样达到锁过期时间的动态扩展。这样的操作方式可能更加偏向于现有框架中的Redisson,有兴趣的朋友可以去尝试使用一下,在此不做详细介绍,下面是其基本的原理图:(图片来源:Java架构-拜托,面试请不要再问我Redis分布式锁的实现原理)
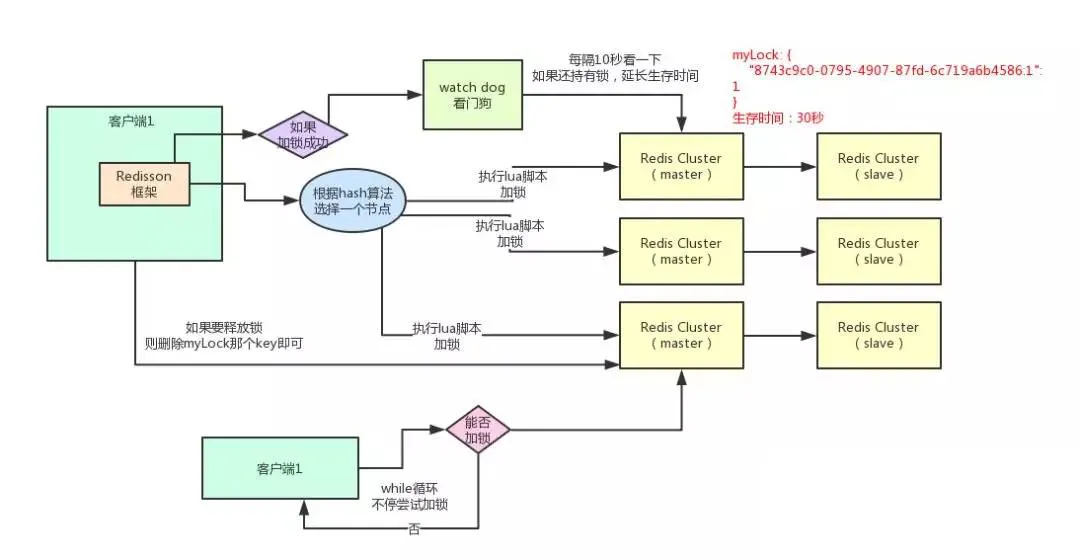
详细代码:https://github.com/YiNanXiangBei/tanyunshou
本文参考